
【第5回】生成 AI の開発・学習と法的問題② - 生成 AI システム開発契約に関する留意点 -
October 15th, 2024
今回の目的
前回の記事では、生成AIの開発・学習における著作権に関する問題を検討しました。 本記事では、生成AIシステム開発契約に関する留意点について説明いたします。
開発の概要
生成AIシステムを自ら開発しようとする場合、大規模言語モデル(LLM)のような学習済みモデルを一から作るという場合はやや例外的で、むしろ既存の学習済みモデルに対して、新たな層を追加し、独自のデータを追加学習させる「ファインチューニング」と呼ばれる手法をとることが多いでしょう(これにより、既存の学習モデルでは対応できなかった特定のタスクやユースケースに合わせて、モデルを調整することが可能です)。
さらに、AIの利用にニーズを感じている事業者(ユーザー企業)が、生成AIシステムの開発(さらにこれを含むシステムの開発)を、AI開発に特化したベンダーに依頼するパターンが多いと思われます。
この場合、ユーザー企業とベンダーの間では、開発委託(請負)、開発委託(準委任)、共同開発といった枠組みで契約が締結されることが考えられます。契約の中では、契約の目的、成果物の帰属(とりわけ、横展開の可否)、データの取扱い等を、各枠組みの性質に応じて定めることになります。
学習用データセットの取扱い
上記のようなケースでは、ユーザー企業がファインチューニングのための追加学習に必要なデータを収集し、ベンダーに提供することが一般的です。このとき、ベンダーは、提供されたデータを適切に加工して、追加学習用のデータセットを(以下「学習用データセット」)作成します。学習用データセットの作成には、ベンダーのノウハウが利用される場合も多いため、提供データはユーザー企業のものであっても、ベンダーとしては学習用データセットを横展開(ここでは、当該ユーザー企業向けのプロジェクトに限らず、他のプロジェクト広く転用することを意味しています。)したいと考えるケースがあります。
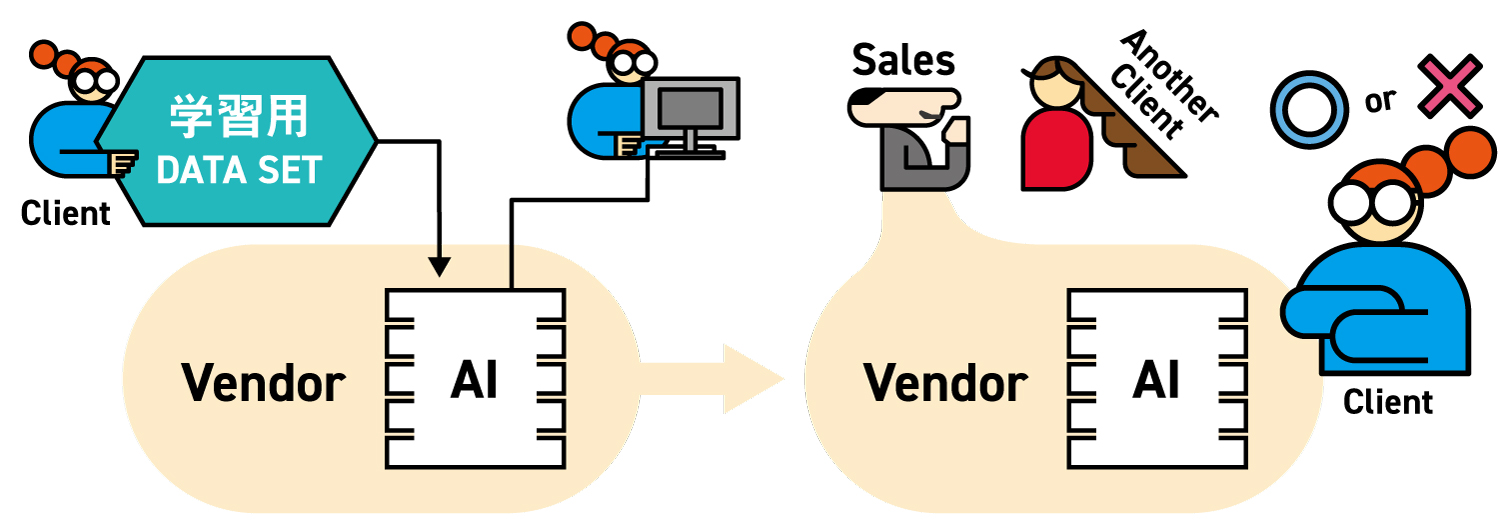
そこで、契約においては、作成された学習用データセットに対する双方の利用権限を明確に定めておくことが非常に有用です。ただし、提供データに個人情報が含まれる場合には、ベンダーの利用権限を広く認めることは、個人情報の利用目的規制や第三者提供規制との関係で、データ主体の同意等が必要となり現実的ではない場合も多いため、注意が必要です。
なお、実際のプロジェクトにおいては、正式の開発委託契約または共同開発契約を締結する前に、開発の見通しを立てるためにテスト開発が先行する場合が多いと思われます。ここで、一般的なNDA(秘密保持契約)を締結しているだけ、あるいはNDAすら締結せずに、かかるテスト開発を行ってしまっている場合はないでしょうか。データの提供や、学習用データセットの作成が行われており、かつ一定の成果物が生じる可能性もある以上、当事者間でそれなりの合意が必要です。このような場合、例えば技術検証契約(PoC契約)という名称で、テストの実施のための必要な事項を取り決めることをお勧めしています。
なお、経済産業省が公開している「AI・データの利用に関する契約ガイドライン─AI編─」 に記載された雛形及び条項解説や、経済産業省の オープンイノベーションポータルサイト において公開されている雛形なども、参考になるでしょう。
成果物(学習済みパラメータ・学習済みモデル等)の保護
AI開発では、学習用データセットを利用して追加学習が行われる結果、得られるデータ・係数(学習済みパラメータ)と、学習済みパラメータを組み込んだ推論プログラム(組み込まれた学習済みパラメータを適用することにより、入力に対して一定の結果が出力されることを可能にするプログラム)(学習済みパラメータを組み込んだ推論プログラムを総称して学習済みモデル)が作成されます。
ここで、学習済みパラメータそのものは、プログラムでも、人が選択したデータベースでもないことから、著作権法の保護を受けることは難しいと考えられています。他方、学習済みモデルのうちプログラムの部分(ソースコード)は、プログラムの著作物として、著作権法上の保護を受け得ると考えられます。そこで、学習済みパラメータも学習済みモデルの一部であって、著作権法上の保護を受けられないかが議論されていますが、いまだ明確な結論は出ておらず、不透明な状況です。
そこで、少なくとも当事者間においては、契約において権利帰属・許諾範囲を明確に定めておくことが有用です。また、ベンダーとしては、ユーザー企業に学習済みモデルのソースコードを開示しないことにより、情報管理の観点から実質的な保護を図ることも考えられるでしょう。なお、開発のベースにするAIモデルには一定の利用条件(ライセンス条件)が定められていることが一般的です。にもかかわらず、特にオープンソースのモデルの場合、当該利用条件による制約が意識されず、当然に再頒布等できると思われているケースが少なくありません。ユーザー企業としては、そういった制約の有無及び内容について正確に把握しておくことが必要です。
他方で、ベンダーやユーザー企業の双方とも、作成したAIの学習済みモデルを、当初の目的の範囲を超えて、自社グループ内で広く展開したり、第三者に販売する製品に組み込むなど、横展開したいというニーズもあると思います。それを可能とするためには、あらかじめ将来の幅広い利活用を想定した契約を締結しておくことが重要です。
最後に
以上を踏まえ、各企業様においては、自信をもって使用できる契約の雛形を作成しておくことが有用です。加えて、プロジェクトごとに、その目的や狙い、背景事情は様々ですから、それらを適切に契約に落とし込むことが必要です。自社のみでの対応が難しい場合は、この分野に精通した弁護士に相談されることをお勧めいたします。もちろん北浜法律事務所のITプラクティスグループでも喜んで対応させていただきます。
今後の予定
- 生成AIに対する規制の現在と今後
- 生成AIの社内利用に関するルール作りのポイント
本記事の内容は、公開日現在のものです。最新の内容とは異なる場合がありますので、ご了承ください。


